OpenAI Whisperを使いましょう
Python のインストール
FFmpeg のインストール
以下サイトから Windows 用ビルドを ZIP 形式でダウンロード
ZIP を適当なフォルダ(例: C:\tools\ffmpeg)に展開
システム環境変数 PATH に C:\tools\ffmpeg\bin を追加
# PATH 追加後、PowerShell を再起動して確認 ffmpeg -version # → バージョン情報が表示されれば OK
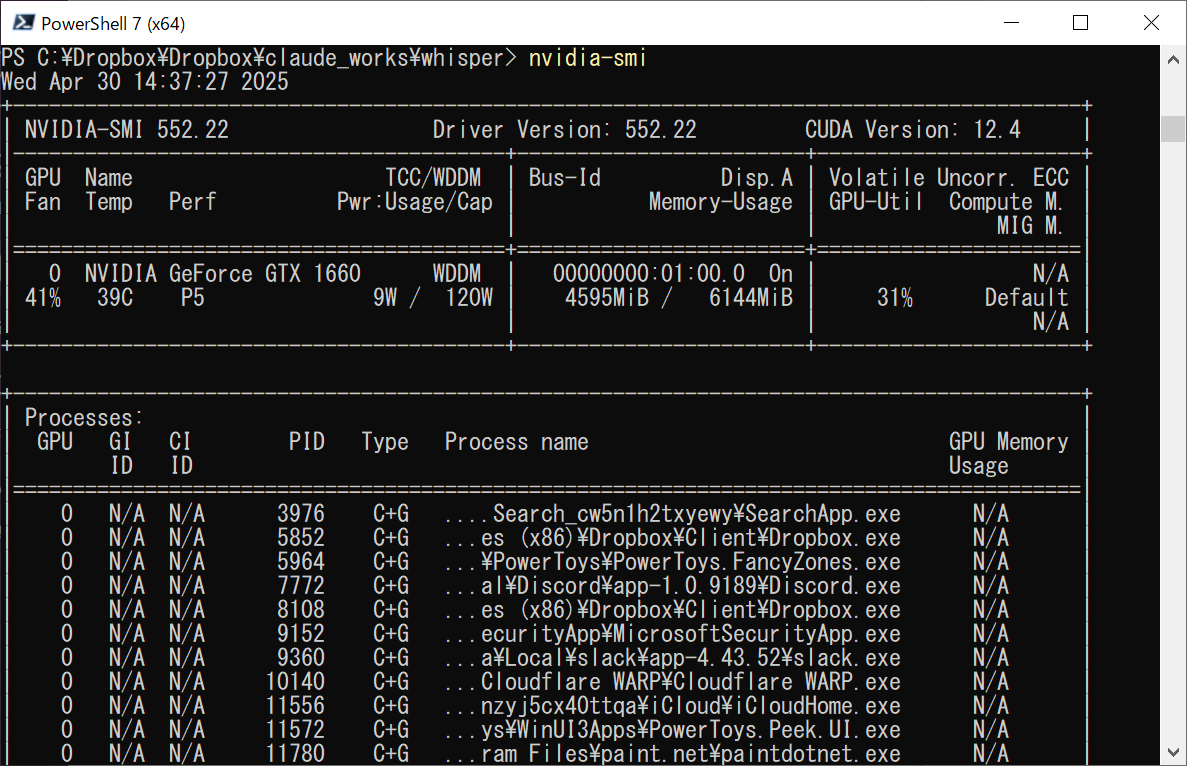
CUDA 11.8 が動作するかどうか確認
powershell
nvidia-smi
CUDA Version: の項目を確認する
PyTorch(+CUDA)と Whisper のインストール
CPUのみ
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
CUDA 11.8対応 GPU がある場合
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
その後、Whisper をインストール
pip install --upgrade pip pip install git+https://github.com/openai/whisper.git
文字起こしするpyファイル作成
generate_subtitles.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import whisper
import argparse
import os
def format_timestamp(seconds: float) -> str:
"""SRT 用のタイムスタンプに変換 (hh:mm:ss,mmm)"""
hours = int(seconds // 3600)
minutes = int((seconds % 3600) // 60)
secs = int(seconds % 60)
milliseconds = int((seconds - int(seconds)) * 1000)
return f"{hours:02}:{minutes:02}:{secs:02},{milliseconds:03}"
def write_srt(segments: list, filepath: str):
"""Whisper の出力 segments から SRT ファイルを生成"""
with open(filepath, 'w', encoding='utf-8') as f:
for idx, seg in enumerate(segments, start=1):
start = format_timestamp(seg['start'])
end = format_timestamp(seg['end'])
text = seg['text'].strip()
f.write(f"{idx}\n{start} --> {end}\n{text}\n\n")
def main():
parser = argparse.ArgumentParser(
description="Whisperで動画から日本語字幕(.srt)を自動生成するツール"
)
parser.add_argument("input", help="入力動画ファイル (.mp4/.mkv/.avi 等)")
parser.add_argument(
"-m", "--model", default="small",
help="Whisperモデル名: tiny, base, small, medium, large (デフォルト: small)"
)
parser.add_argument(
"-o", "--output",
help="出力 SRT ファイル名 (デフォルト: 入力ファイル名ベースで .srt)"
)
args = parser.parse_args()
inp = args.input
out = args.output or os.path.splitext(inp)[0] + ".srt"
print(f"[1/3] モデル「{args.model}」をロードしています…")
model = whisper.load_model(args.model)
print(f"[2/3] 「{inp}」を文字起こし中… (言語: 日本語)")
result = model.transcribe(inp, language="ja")
print(f"[3/3] SRT を書き出しています: {out}")
write_srt(result["segments"], out)
print("✅ 完了しました!")
if __name__ == "__main__":
main()
文字起こしする
python generate_subtitles.py <文字起こししたいmp4ファイル>
.srtファイルが作成されます